Árvores de Decisão e Florestas Aleatórias na Prática
Introdução
A maioria das técnicas de aprendizado supervisionado processa o vetor de features inteiro de uma só vez: seja por projeções lineares (como na regressão), seja por distâncias a exemplos de treino (como no k-NN).
As árvores de decisão seguem um caminho diferente. Elas executam uma sequência de operações simples, muitas vezes olhando para um único elemento do vetor por vez, antes de decidir qual elemento examinar em seguida.
Neste artigo vamos entender a matemática por trás dessa partição (entropia e ganho de informação) e ver por que sua extensão mais poderosa, a floresta aleatória (random forest), generaliza melhor que uma única árvore. Ao final, treinamos ambas em Python com scikit-learn.
A Intuição Geométrica
Como os classificadores baseados em margem (SVM), as árvores de decisão são classificadores discriminativos: elas nunca constroem explicitamente um modelo probabilístico (gerativo) dos dados.
A figura abaixo resume a ideia. Os exemplos de treino vêm de quatro classes diferentes (uma cor cada). A árvore é construída de cima para baixo, escolhendo em cada nó a decisão que separa os exemplos em distribuições mais específicas, de menor entropia.
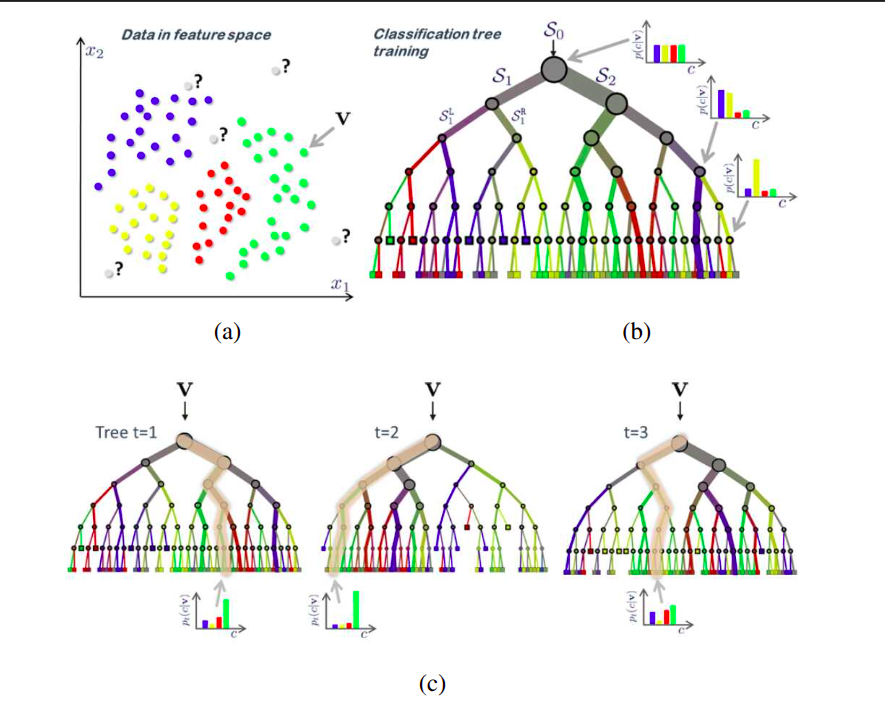
Árvores de decisão e florestas (adaptado de Criminisi e Shotton, 2013). Em (b), a espessura de cada ligação indica quantas amostras seguem aquele caminho, e a cor é a mistura das classes que fluem por ele. Em (c), cada exemplo é classificado por todas as árvores e as distribuições das folhas são promediadas.
Durante o teste, cada novo exemplo (vetor de features) é avaliado no nó raiz. Dependendo do resultado do teste (por exemplo, a comparação de um elemento com um limiar), descemos para um dos nós filhos. Isso continua até alcançar uma folha com uma distribuição de classes específica.
Fundação Teórica: Entropia
Para construir uma boa árvore precisamos medir quão "misturado" está um conjunto de exemplos. A ferramenta clássica é a entropia de Shannon.
Seja o conjunto de amostras que chegaram a um nó, e a fração dessas amostras pertencentes à classe . A entropia é:
A intuição é direta:
- Se todas as amostras são da mesma classe, : pureza máxima.
- Se as classes estão igualmente distribuídas, : incerteza máxima.
Ganho de Informação
Uma decisão em um nó divide em subconjuntos filhos . Queremos a decisão que mais reduz a entropia média dos filhos. Essa redução é o ganho de informação:
O termo pondera cada filho pela proporção de amostras que ele recebe. O algoritmo de treino testa candidatos a divisão (qual feature, qual limiar) e escolhe o que maximiza .
Uma Alternativa: a Impureza de Gini
Na prática, muitas implementações (incluindo o scikit-learn por padrão) usam a impureza de Gini em vez da entropia, por ser mais barata de calcular (não exige logaritmos):
Ambas as métricas levam a árvores semelhantes na maioria dos casos. A lógica é a mesma: escolher a divisão que torna os filhos mais puros.
Desenvolvimento: Construindo a Árvore
O treinamento é um processo guloso e recursivo:
Passo 1: No nó atual, para cada feature e cada limiar candidato, simule a divisão versus .
Passo 2: Calcule o ganho de informação de cada divisão candidata.
Passo 3: Escolha a divisão com maior e crie os dois nós filhos.
Passo 4: Repita recursivamente em cada filho, parando quando o nó for puro, atingir a profundidade máxima , ou ficar com poucas amostras.
O parâmetro mais importante aqui é a profundidade . Árvores rasas capturam apenas padrões grosseiros (alto viés); árvores muito profundas decoram o ruído do treino (alta variância, overfitting).
Florestas Aleatórias
Uma única árvore profunda é instável: pequenas mudanças nos dados produzem árvores bem diferentes. A solução é construir um conjunto (ensemble) de árvores, cada uma tomando decisões ligeiramente diferentes: a floresta aleatória.
No tempo de teste, um novo exemplo é classificado por todas as árvores, e as distribuições de classe das folhas finais são promediadas:
Essa média produz uma resposta mais precisa do que se obteria com uma única árvore de mesma profundidade, e fronteiras de decisão mais suaves.
Os Parâmetros de Projeto
As florestas têm parâmetros que ajustam acurácia, generalização e custo computacional:
- : a profundidade de cada árvore.
- : o número de árvores na floresta.
- : o número de hipóteses (features/limiares) examinadas ao construir cada nó.
O parâmetro é a chave da aleatoriedade. Ao olhar apenas um subconjunto aleatório das possibilidades em cada nó, cada árvore acaba com funções de decisão distintas, e o ensemble pode ser promediado para gerar fronteiras mais "macias".
Há um trade-off claro: menos aleatoriedade (um grande, ex.: ) produz fronteiras mais nítidas, que podem não generalizar tão bem; mais aleatoriedade () suaviza a fronteira e tende a generalizar melhor.
Como em todo aprendizado de máquina, desempenho melhor nos dados de treino não implica melhor generalização: o fantasma do overfitting está sempre presente.
Vale notar ainda que substituir decisões alinhadas aos eixos (comparar um único elemento a um limiar) por combinações lineares de features produz fronteiras diagonais mais expressivas: os chamados weak learners lineares.
Aplicações em Visão Computacional
Embora árvores existam na estatística desde os anos 1980 (Breiman, Friedman et al., 1984), as florestas só ganharam tração em visão computacional há pouco mais de uma década.
- Reconhecimento de keypoints (Lepetit e Fua, 2006), uma das primeiras aplicações de impacto.
- Segmentação de imagens (Shotton, Johnson e Cipolla, 2008).
- Estimação de pose humana a partir de imagens de profundidade do Kinect (Shotton, Girshick et al., 2013): combinada a uma quantidade massiva de dados sintéticos de treino, foi um marco da área.
- Segmentação de imagens médicas (Criminisi, Robertson et al., 2013), hoje em grande parte substituída por redes neurais profundas.
Exemplo de Uso em Python
Vamos treinar uma árvore e uma floresta sobre um problema clássico e comparar a acurácia. O scikit-learn torna isso direto.
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Dataset: 178 vinhos descritos por 13 features químicas, 3 classes
features, labels = load_wine(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
features, labels, test_size=0.3, random_state=42
)
# Uma única árvore, com profundidade limitada (D = 4)
tree = DecisionTreeClassifier(
criterion="entropy", # usa ganho de informação (entropia de Shannon)
max_depth=4,
random_state=42,
)
tree.fit(X_train, y_train)
acc_tree = accuracy_score(y_test, tree.predict(X_test))
# Uma floresta com T = 400 árvores
forest = RandomForestClassifier(
n_estimators=400, # T = número de árvores
max_depth=4, # D = profundidade de cada árvore
max_features="sqrt", # controla rho: subconjunto de features por nó
random_state=42,
)
forest.fit(X_train, y_train)
acc_forest = accuracy_score(y_test, forest.predict(X_test))
print(f"Acurácia da árvore única: {acc_tree:.3f}")
print(f"Acurácia da floresta: {acc_forest:.3f}")
Com a mesma profundidade , a floresta tipicamente supera a árvore única, exatamente o efeito de promediar muitas hipóteses ligeiramente diferentes.
Inspecionando o que a Floresta Aprendeu
Um bônus prático das florestas é a importância das features, derivada de quanto cada feature reduz a impureza ao longo de todas as árvores:
import numpy as np
importances = forest.feature_importances_
for idx in np.argsort(importances)[::-1][:5]:
print(f"Feature {idx}: {importances[idx]:.3f}")
Isso ajuda a interpretar o modelo, algo que redes neurais raramente entregam de forma tão direta.
Conclusão
Árvores de decisão trocam projeções globais por uma cascata de testes simples, escolhidos para reduzir a entropia (ou a impureza de Gini) a cada nó. Florestas aleatórias combinam muitas árvores diversificadas, promediando suas previsões para ganhar acurácia e generalização.
Os três botões que você vai ajustar na prática são , e , e o equilíbrio entre eles é, no fundo, o eterno trade-off entre viés e variância.
Próximos passos: explore gradient boosting (que constrói árvores sequencialmente, corrigindo os erros das anteriores) e revisite a base vetorial em A Beleza da Álgebra Linear, já que toda feature aqui é, no fim, uma coordenada em .
Referências: Criminisi e Shotton (2013); Hastie, Tibshirani e Friedman (2009, Cap. 17); Szeliski, Computer Vision: Algorithms and Applications, 2ª ed. (2021), Seção 5.1.
Gostou deste artigo? Inscreva-se na newsletter.