Cálculo em Deep Learning: de Limites a Gradientes
Introdução
Se a álgebra linear é o "cavalo de batalha" que organiza dados em vetores e matrizes, o cálculo é o motor que coloca o aprendizado em movimento. Toda vez que uma rede neural ajusta um peso, há uma derivada por trás. Toda vez que um filtro desliza sobre uma imagem, há uma integral (ou sua versão discreta) sendo calculada.
Neste artigo, partimos das três ideias fundamentais do cálculo (limites, derivadas e integrais) e então mergulhamos nas situações em que elas aparecem com mais força em deep learning e visão computacional. O objetivo não é o rigor de um curso de análise, mas a intuição de por que essas ferramentas são indispensáveis.
Os Três Pilares do Cálculo
Limites: a Ideia de Aproximação
Um limite descreve para onde uma função "tende" quando sua entrada se aproxima de um valor, mesmo que ela nunca chegue exatamente lá. Formalmente:
significa que fica arbitrariamente próximo de conforme se aproxima de . Limites são a fundação sobre a qual derivadas e integrais são construídas: ambas são, no fundo, limites de processos de aproximação.
Em deep learning, os limites aparecem de forma sutil mas constante: a própria definição de derivada (que move o gradiente descendente) é um limite, e fenômenos como o gradiente que desaparece (vanishing gradient) são, em essência, comportamentos de limite das funções de ativação quando suas entradas vão para .
Simulador de Limites
| Métrica | Posição Atual | Distância Restante (Erro) |
|---|---|---|
| Eixo X (Domínio) | x' = 0.8000 | |x' - a| = 1.2000 |
| Eixo Y (Imagem) | f(x') = 0.6400 | |f(x') - L| = 3.3600 |
* Observe analiticamente: Conforme a distância no domínio |x' - a| encolhe em direção a zero, a distância na imagem |f(x') - L| também é forçada a diminuir, demonstrando o comportamento do limite.
Derivadas: a Taxa de Variação
A derivada mede quão rápido uma função muda. É definida exatamente como o limite da inclinação de retas secantes:
Geometricamente, é a inclinação da reta tangente ao gráfico no ponto . Se a derivada é positiva, a função cresce; se é negativa, decresce; se é zero, estamos em um ponto crítico (mínimo, máximo ou sela).
Essa interpretação, "para que lado e com que intensidade a função muda", é precisamente o que o treinamento de redes neurais explora para minimizar o erro.
Integrais: a Acumulação
Se a derivada decompõe a variação, a integral a acumula. A integral definida de uma função entre e corresponde à área sob a sua curva:
O Teorema Fundamental do Cálculo amarra os dois conceitos: integração e diferenciação são operações inversas. Em deep learning, integrais aparecem sempre que precisamos somar contribuições contínuas: probabilidades, valores esperados e, na versão discreta, as convoluções que processam imagens.
Aprofundando nas Derivadas
Em deep learning, é nas derivadas que o cálculo realmente brilha. Vamos detalhar os conceitos que sustentam o gradiente descendente.
Derivadas Parciais e o Gradiente
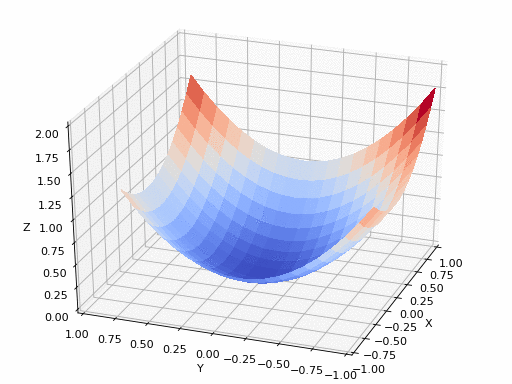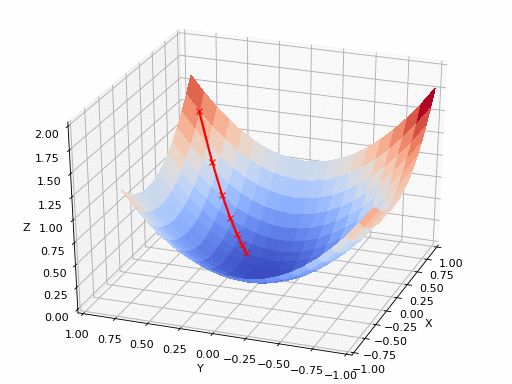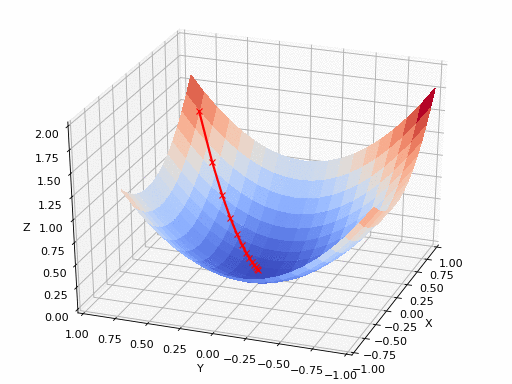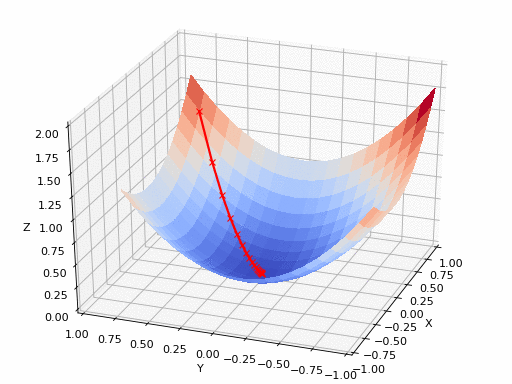
Uma rede neural não tem um único parâmetro, mas milhões. A função de perda depende de todos eles. Para saber como cada peso individual afeta a perda, usamos derivadas parciais: a derivada em relação a uma variável, mantendo as demais fixas:
Empilhando todas as derivadas parciais em um vetor, obtemos o gradiente:
O gradiente aponta na direção de maior crescimento da perda. Como queremos minimizá-la, caminhamos no sentido oposto, daí o nome gradiente descendente:
onde é a taxa de aprendizado. Essa única equação é o coração do treinamento de praticamente todo modelo moderno.
A Regra da Cadeia e a Backpropagation
Uma rede profunda é uma composição de funções: a saída de uma camada é a entrada da próxima. Para derivar uma composição, usamos a regra da cadeia:
A backpropagation nada mais é do que a aplicação sistemática da regra da cadeia, propagando a derivada da perda da camada de saída de volta até as primeiras camadas. Para uma rede com camadas , :
Cada fator é uma derivada local, calculada durante o forward pass e reutilizada no backward pass. Esse reaproveitamento é o que torna o treinamento de redes gigantes computacionalmente viável. Exploramos essa mecânica em detalhe em Redes Neurais Profundas: do Perceptron ao Fim a Fim.
Derivadas das Funções de Ativação
A escolha da função de ativação tem tudo a ver com sua derivada, porque é a derivada que flui na backpropagation.
A derivada da sigmoide é no máximo e tende a zero nas extremidades. Em redes profundas, multiplicar muitos desses valores pequenos faz o gradiente desaparecer, um problema clássico que travava o treinamento.
A derivada da ReLU é para entradas positivas: o gradiente passa sem ser atenuado. É por isso que a ReLU se tornou a opção padrão em redes profundas.
A derivada da sigmoide é no máximo e tende a zero nas extremidades, exatamente o que o gráfico interativo abaixo mostra. Passe o mouse sobre a curva para inspecionar os valores:
Compare a sigmoide com sua derivada (no máximo 0,25): é esse achatamento que provoca o vanishing gradient em redes profundas.
Exemplo em Python: Derivada Numérica vs. Analítica
Podemos verificar uma derivada calculando-a tanto pela fórmula do limite quanto pela expressão analítica.
import numpy as np
def sigmoide(z):
return 1 / (1 + np.exp(-z))
def sigmoide_derivada(z): # forma analítica
s = sigmoide(z)
return s * (1 - s)
def derivada_numerica(f, z, h=1e-6): # aproximação pelo limite
return (f(z + h) - f(z - h)) / (2 * h)
z = 0.8
print(f"Derivada analítica: {sigmoide_derivada(z):.6f}")
print(f"Derivada numérica: {derivada_numerica(sigmoide, z):.6f}")
As duas saídas coincidem até várias casas decimais, exatamente o que a definição de derivada como limite nos promete. Frameworks como PyTorch e TensorFlow automatizam isso com diferenciação automática (autograd), montando o grafo de operações e aplicando a regra da cadeia sem que precisemos derivar à mão.
Aprofundando nas Integrais
As integrais são menos visíveis no dia a dia do treinamento, mas estão no centro da visão computacional e da teoria probabilística por trás das perdas.
Convolução: a Integral que Processa Imagens
A operação mais emblemática da visão computacional é a convolução. Em sua forma contínua, ela é literalmente uma integral que combina duas funções, deslizando uma sobre a outra:
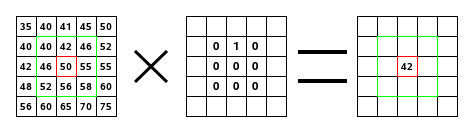
Em imagens digitais, trabalhamos com a versão discreta, onde a integral vira um somatório. Um pequeno kernel (filtro) desliza sobre a imagem, e em cada posição calculamos uma soma ponderada dos pixels vizinhos:
Dependendo dos pesos do kernel, a convolução pode borrar, aguçar ou detectar bordas. As redes convolucionais (CNNs) aprendem esses kernels automaticamente durante o treino, em vez de defini-los à mão.
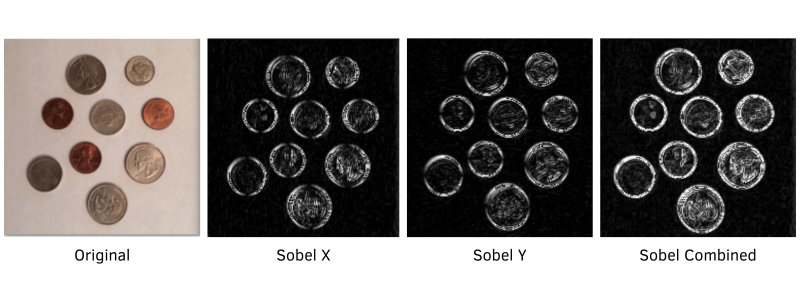
Detecção de Bordas como Derivada de Imagem
Aqui derivadas e integrais se encontram de forma elegante. Uma borda em uma imagem é uma mudança brusca de intensidade, ou seja, uma região de derivada alta. Para detectá-la, calculamos o gradiente da imagem, aproximando as derivadas parciais por convoluções com kernels como o de Sobel:
A magnitude do gradiente, , realça os contornos. Note a bela conexão: usamos uma convolução (integral discreta) para estimar uma derivada da imagem.
Integrais na Probabilidade e nas Funções de Perda
Quando a saída de um modelo é uma distribuição de probabilidade contínua, integrais aparecem para garantir que tudo "some 1" e para calcular valores esperados:
A perda de entropia cruzada, usada em classificação, deriva da teoria da informação, onde a entropia de uma variável contínua é definida por uma integral. Na prática, com classes discretas, ela vira um somatório, mas o fundamento conceitual é integral.
Exemplo em Python: Convolução para Detectar Bordas
import numpy as np
from scipy import ndimage
# Imagem sintética: um quadrado claro sobre fundo escuro
imagem = np.zeros((100, 100))
imagem[30:70, 30:70] = 1.0
# Kernel de Sobel para detectar bordas horizontais e verticais
sobel_x = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]])
sobel_y = sobel_x.T
# Convolução estima as derivadas parciais da imagem
gx = ndimage.convolve(imagem, sobel_x)
gy = ndimage.convolve(imagem, sobel_y)
# Magnitude do gradiente realça os contornos
bordas = np.sqrt(gx**2 + gy**2)
print(f"Intensidade máxima de borda: {bordas.max():.2f}")
print(f"Pixels detectados como borda: {(bordas > 0.5).sum()}")
O resultado destaca exatamente os limites do quadrado: onde a intensidade muda, a derivada é alta, e a convolução a captura.
Conclusão
Cálculo e deep learning são inseparáveis. Limites dão sentido formal à variação infinitesimal; derivadas dizem em que direção ajustar cada parâmetro e movem o gradiente descendente via regra da cadeia; integrais acumulam contribuições e, na forma discreta de convoluções, processam imagens e detectam estruturas.
Da backpropagation que treina bilhões de parâmetros aos filtros que enxergam bordas, o mesmo punhado de ideias do cálculo está sempre em ação. Entender essa base não só desmistifica o que os frameworks fazem por baixo dos panos, como também dá intuição para diagnosticar problemas como gradientes que desaparecem ou explodem.
Próximos passos: combine essa base com a Álgebra Linear, que organiza esses cálculos em operações vetoriais e matriciais eficientes, e veja como tudo se junta nas Redes Neurais Profundas.
Referências: Stewart, Calculus (2015); Goodfellow, Bengio e Courville, Deep Learning (2016, Caps. 4 e 6); Szeliski, Computer Vision: Algorithms and Applications, 2ª ed. (2021), Seções 3.2 e 5.3.
Gostou deste artigo? Inscreva-se na newsletter.